Extract your scientific profile with R
Made a fancy figure for job/grant applications summarizing my publications and really proud of how it turned out (apologies for the bragging, but also, hire me). pic.twitter.com/D0je3PW1uF
— Alvaro L Perez-Quintero (@alperezqui) February 25, 2021
Alvaro code to build this figure is available on GitHub (code)
What do you need?
First of all, you need to update your Google Scholar profile. Google will automatically detect all your publications. You can allow Google to update your profile automatically (here); however, if you have a common name or share it with another scientist, this may be tricky.
Once your Google Scholar profile is up-to-date, you will need your Google Scholar ID. To find it, go on your Google Scholar page; you will find your ID in the URL between “user=” and “&”. For example, my URL is: https://scholar.google.com/citations?user=fEd4WGYAAAAJ&hl=en, so my ID is: “fEd4WGYAAAAJ”.
Now we are ready to start!
Packages
We will need to extract our scientific profile the R packages scholar and easyPubMed. The first will allow us the extract our scientific profile from Google Scholar, and the second to have more in-depth information about the articles on PubMed.
libs <- c(
'dplyr',
'ggplot2',
'scholar',
'easyPubMed'
)
invisible(lapply(libs, library, character.only = T))Data collection
Extraction of your scientific publication from Google Scholar
The package scholar is pretty handy, we will use the function get_publication() to extract the list of publications from Google Scholar. This function will reference your publications, titles, 5-6 first authors, journal, journal references (volume, pages), number of citations, year, and two Google Scholar ID “cid” and “pubid”. the latest been the Google Scholar reference of your publication. This “pubid” will be useful in other scholar function like get_complete_authors().
scholar.id = "fEd4WGYAAAAJ"
pub = get_publications(scholar.id)
pub## title
## 1 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 2 Plant functional trait identity and diversity effects on soil meso-and macrofauna in an experimental grassland
## 3 Do invasive earthworms affect the functional traits of native plants?
## 4 Diplôme de Master 2 Mention Biodiversité—Écologie—Évolution Parcours DARWIN: Biologie Évolutive & Écologie
## author
## 1 S Cesarz, AE Schulz, R Beugnon, N Eisenhauer
## 2 R Beugnon, K Steinauer, AD Barnes, A Ebeling, C Roscher, ...
## 3 L Thouvenot, O Ferlian, R Beugnon, T Künne, A Lochner, MP Thakur, ...
## 4 R Beugnon
## journal number cites year cid
## 1 Soil organisms 91 (2), 61 5 2019 9973965598904659566
## 2 Advances in Ecological Research 61, 163-184 4 2019 3770229238311880035
## 3 Frontiers in Plant Science 12, 424 0 2021 <NA>
## 4 Montpellier SupAgro 0 2018 <NA>
## pubid
## 1 2osOgNQ5qMEC
## 2 9yKSN-GCB0IC
## 3 qjMakFHDy7sC
## 4 d1gkVwhDpl0CAs the information provided by the Google Scholar are quite limited, we will use the easyPubMed to extract more information about the artible.
Get the full references of each article
As exemple, Google Scholar doesn’t provide the affilation of your co-authors. Therefore, we will extract this information from PubMed.
- Find your article on PubMed using its title
1.1 Find the title in “pub”
title = pub$title[1]
title## [1] "Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method"1.2 Use get_pubmed_ids_by_fulltitle() function to built your PubMed request
my_request <- get_pubmed_ids_by_fulltitle(title, field = "[Title]")
my_request## $Count
## [1] "1"
##
## $RetMax
## [1] "1"
##
## $RetStart
## [1] "0"
##
## $QueryKey
## [1] "1"
##
## $WebEnv
## [1] "MCID_6051d4074895d2738970a529"
##
## $IdList
## $IdList$Id
## [1] "32607134"
##
##
## $QueryTranslation
## [1] "testing[Title] AND soil[Title] AND nematode[Title] AND extraction[Title] AND efficiency[Title] AND different[Title] AND variations[Title] AND baermann-funnel[Title] AND method[Title]"
##
## $TranslationSet
## list()
##
## $OriginalQuery
## [1] "testing[Title]+AND+soil[Title]+AND+nematode[Title]+AND+extraction[Title]+AND+efficiency[Title]+AND+different[Title]+AND+variations[Title]+AND+baermann-funnel[Title]+AND+method[Title]"1.3 Use fetch_pubmed_data() function to fetch the reference
The function will return a string of characters with all PubMed data in the xml format. However, some of your articles may not be available on PubMed, for example, thesis, gray literature, or small journals. When this is the case, either the information needed is available on Google Scholar and you can use the scholar package functions to grep them, or you may need to proceed manually to fill your dataset.
my_xml <- fetch_pubmed_data(my_request)
my_xml## [1] "<?xml version=\"1.0\" ?><!DOCTYPE PubmedArticleSet PUBLIC \"-//NLM//DTD PubMedArticle, 1st January 2019//EN\" \"https://dtd.nlm.nih.gov/ncbi/pubmed/out/pubmed_190101.dtd\"><PubmedArticleSet><PubmedArticle> <MedlineCitation Status=\"PubMed-not-MEDLINE\" Owner=\"NLM\"> <PMID Version=\"1\">32607134</PMID> <DateRevised> <Year>2021</Year> <Month>01</Month> <Day>10</Day> </DateRevised> <Article PubModel=\"Print-Electronic\"> <Journal> <ISSN IssnType=\"Print\">1864-6417</ISSN> <JournalIssue CitedMedium=\"Print\"> <Volume>91</Volume> <Issue>2</Issue> <PubDate> <Year>2019</Year> <Month>Aug</Month> <Day>01</Day> </PubDate> </JournalIssue> <Title>Soil organisms</Title> <ISOAbbreviation>Soil Org</ISOAbbreviation> </Journal> <ArticleTitle>Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method.</ArticleTitle> <Pagination> <MedlinePgn>61-72</MedlinePgn> </Pagination> <ELocationID EIdType=\"doi\" ValidYN=\"Y\">10.25674/so91201</ELocationID> <Abstract> <AbstractText>Nematodes are increasingly used as powerful bioindicators of soil food web composition and functioning in ecological studies. Todays' ecological research aims to investigate not only local relationships but global patterns, which requires consistent methodology across locations. Thus, a common and easy extraction protocol of soil nematodes is needed. In this study, we present a detailed protocol of the Baermann-funnel method and highlight how different soil pre-treatments and equipment (soil type, soil height, sieving, and filter type) can affect extraction efficiency and community composition by using natural nematode communities. We found that highest nematode extraction efficiency was achieved using lowest soil height as indicated by the thickness of the soil sample in the extractor (1, 2, or 4 cm soil height) in combination with soil sieving (instead of no sieving), and by using milk filters (instead of paper towels). PCA at the family level revealed that different pre-treatments significantly affected nematode community composition. Increasing the height of the soil sample by adding more soil increased the proportion of larger-sized nematodes likely because those are able to overcome long distances but selected against small nematodes. Sieving is suggested to break up soil aggregates and, therefore, facilitate moving in general. Interestingly, sieving did not negatively affect larger nematodes that are supposed to have a higher probability of getting bruised during sieving but, even if not significant, tended to yield more extracted nematodes than no sieving. We therefore recommend to use small heights of sieved soil with milk filter to extract free-living soil nematodes with the Baermann-funnel method. The present study shows that variations in the extraction protocol can alter the total density and community composition of extracted nematodes and provides recommendations for an efficient and standardized approach in future studies. Having a simple, cheap, and standardized extraction protocol can facilitate the assessment of soil biodiversity in global contexts.</AbstractText> </Abstract> <AuthorList CompleteYN=\"Y\"> <Author ValidYN=\"Y\"> <LastName>Cesarz</LastName> <ForeName>Simone</ForeName> <Initials>S</Initials> <AffiliationInfo> <Affiliation>German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> <AffiliationInfo> <Affiliation>Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> <AffiliationInfo> <Affiliation>Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.</Affiliation> </AffiliationInfo> </Author> <Author ValidYN=\"Y\"> <LastName>Eva Schulz</LastName> <ForeName>Annika</ForeName> <Initials>A</Initials> <AffiliationInfo> <Affiliation>Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.</Affiliation> </AffiliationInfo> </Author> <Author ValidYN=\"Y\"> <LastName>Beugnon</LastName> <ForeName>Rémy</ForeName> <Initials>R</Initials> <AffiliationInfo> <Affiliation>German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> <AffiliationInfo> <Affiliation>Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> </Author> <Author ValidYN=\"Y\"> <LastName>Eisenhauer</LastName> <ForeName>Nico</ForeName> <Initials>N</Initials> <AffiliationInfo> <Affiliation>German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> <AffiliationInfo> <Affiliation>Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.</Affiliation> </AffiliationInfo> <AffiliationInfo> <Affiliation>Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.</Affiliation> </AffiliationInfo> </Author> </AuthorList> <Language>eng</Language> <GrantList CompleteYN=\"Y\"> <Grant> <GrantID>677232</GrantID> <Acronym>ERC_</Acronym> <Agency>European Research Council</Agency> <Country>International</Country> </Grant> </GrantList> <PublicationTypeList> <PublicationType UI=\"D016428\">Journal Article</PublicationType> </PublicationTypeList> <ArticleDate DateType=\"Electronic\"> <Year>2019</Year> <Month>08</Month> <Day>06</Day> </ArticleDate> </Article> <MedlineJournalInfo> <Country>Germany</Country> <MedlineTA>Soil Org</MedlineTA> <NlmUniqueID>101490173</NlmUniqueID> </MedlineJournalInfo> <KeywordList Owner=\"NOTNLM\"> <Keyword MajorTopicYN=\"N\">comparability</Keyword> <Keyword MajorTopicYN=\"N\">extraction methods</Keyword> <Keyword MajorTopicYN=\"N\">reproducibility</Keyword> <Keyword MajorTopicYN=\"N\">soil organisms</Keyword> </KeywordList> </MedlineCitation> <PubmedData> <History> <PubMedPubDate PubStatus=\"entrez\"> <Year>2020</Year> <Month>7</Month> <Day>2</Day> <Hour>6</Hour> <Minute>0</Minute> </PubMedPubDate> <PubMedPubDate PubStatus=\"pubmed\"> <Year>2020</Year> <Month>7</Month> <Day>2</Day> <Hour>6</Hour> <Minute>0</Minute> </PubMedPubDate> <PubMedPubDate PubStatus=\"medline\"> <Year>2020</Year> <Month>7</Month> <Day>2</Day> <Hour>6</Hour> <Minute>1</Minute> </PubMedPubDate> </History> <PublicationStatus>ppublish</PublicationStatus> <ArticleIdList> <ArticleId IdType=\"pubmed\">32607134</ArticleId> <ArticleId IdType=\"doi\">10.25674/so91201</ArticleId> <ArticleId IdType=\"pmc\">PMC7326606</ArticleId> <ArticleId IdType=\"mid\">EMS86615</ArticleId> </ArticleIdList> <?nihms?> <ReferenceList> <Reference> <Citation>Ambio. 2016 Feb;45(1):29-41</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">26264716</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>J Exp Biol. 2000 Aug;203(Pt 16):2467-78</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">10903161</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>J Nematol. 1989 Jul;21(3):370-8</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">19287622</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Annu Rev Phytopathol. 1999;37:127-149</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">11701819</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>J Ecol. 2014 Nov;102(6):1673-1687</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">25558092</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Nature. 2019 Aug;572(7768):194-198</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">31341281</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>J Nematol. 1983 Jul;15(3):450-4</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">19295832</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Oecologia. 1990 May;83(1):14-19</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">28313236</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Nat Microbiol. 2018 Feb;3(2):189-196</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">29158606</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>J Nematol. 1993 Sep;25(3):315-31</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">19279775</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Nature. 2019 Aug;572(7768):187-188</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">31384050</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Oecologia. 2017 Jul;184(3):715-728</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">28608023</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Science. 2018 Jan 19;359(6373):320-325</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">29348236</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Nat Ecol Evol. 2017 Mar 23;1(4):103</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">28812674</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>Trends Ecol Evol. 1999 Jun;14(6):224-228</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">10354624</ArticleId> </ArticleIdList> </Reference> <Reference> <Citation>PLoS One. 2013 Jun 18;8(6):e66653</Citation> <ArticleIdList> <ArticleId IdType=\"pubmed\">23825552</ArticleId> </ArticleIdList> </Reference> </ReferenceList> </PubmedData></PubmedArticle></PubmedArticleSet>"- Extract information from a reference
As you can see the output isn’t super handy; the easyPubMed package provide a tool to deal with that: custom_grep(). The function will return the content of specified tag.
For example the affiliation:
custom_grep(my_xml, tag = "Affiliation") %>% unlist## [1] "German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [2] "Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [3] "Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany."
## [4] "Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany."
## [5] "German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [6] "Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [7] "German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [8] "Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany."
## [9] "Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany."For example, you can find the following tags in the output: Year, Journal, ISSN, ArticleTitle, Abstract, AuthorList, Affiliation, Keyword …
- Extraction of all the references
In this example, we will extract the affiliations of the authors from all papers. (This step can take quite some time to be performed)
affiliations = data.frame(matrix(NA, ncol = 2, nrow = 1))
colnames(affiliations) = c('title', 'affiliation')
for(j in 1 : length(pub$title)){
skip_to_next <- FALSE
tryCatch( # I use tryCatch to catch the papers not found on PubMed
{
my_entrez_id <- get_pubmed_ids_by_fulltitle(pub$title[j], field = "[Title]")
my_xml <- fetch_pubmed_data(my_entrez_id)
affiliations = bind_rows(
affiliations,
data.frame(
title = pub$title[j],
affiliation = custom_grep(my_xml, tag = "Affiliation") %>% unlist
)
)
}, error = function(e){
skip_to_next <<- TRUE
}
)
if(skip_to_next) {
affiliations = bind_rows(
affiliations,
data.frame(
title = pub$title[j],
affiliation = "NOT FOUND")
)
next } # To continue the script in the next occurrence
}
affiliations## title
## 1 <NA>
## 2 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 3 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 4 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 5 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 6 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 7 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 8 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 9 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 10 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 11 Plant functional trait identity and diversity effects on soil meso-and macrofauna in an experimental grassland
## 12 Do invasive earthworms affect the functional traits of native plants?
## 13 Diplôme de Master 2 Mention Biodiversité—Écologie—Évolution Parcours DARWIN: Biologie Évolutive & Écologie
## affiliation
## 1 <NA>
## 2 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 3 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 4 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 5 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 6 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 7 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 8 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 9 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 10 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 11 NOT FOUND
## 12 NOT FOUND
## 13 NOT FOUND- Extraction of the cities and countries from the affiliations
Once you have all the affiliations you may like to plot them on a map. For that, you need to extract the cities and countries. The following code is most likely not the most efficient way to do it, but it gives a first idea.
5.1 List of cities
You will need the list of cities with their spatial positions (longitude and latitude). I am using the dataset world.cities from the package maps, but there are a lot of other possibilities.
library(maps)
head(world.cities)## name country.etc pop lat long capital
## 1 'Abasan al-Jadidah Palestine 5629 31.31 34.34 0
## 2 'Abasan al-Kabirah Palestine 18999 31.32 34.35 0
## 3 'Abdul Hakim Pakistan 47788 30.55 72.11 0
## 4 'Abdullah-as-Salam Kuwait 21817 29.36 47.98 0
## 5 'Abud Palestine 2456 32.03 35.07 0
## 6 'Abwein Palestine 3434 32.03 35.20 0We will create a new dataset with all cities
# New dataset
df.cities = data.frame(matrix(NA, ncol = 5, nrow = 1))
colnames(df.cities) = c('affiliation', 'City', 'Country', 'lat', 'long')
for(af in unique(affiliations$affiliation)){
city = world.cities$name[lapply(world.cities$name, function(x) {
grepl(pattern = x,
x = af,
fixed = T)}) %>% unlist]
country = world.cities$country.etc[lapply(world.cities$country.etc, function(x) {
grepl(pattern = x,
x = af,
fixed = T)}) %>% unlist]
c =
world.cities %>%
mutate(affiliation = af) %>%
filter(name %in% city & country.etc %in% country) %>%
select(affiliation, City = name, Country = country.etc, lat, long) %>%
filter(!duplicated(City)) # To remove multiple entries
df.cities = bind_rows(
df.cities,
c
)
}
affiliations = left_join(affiliations, df.cities, by = "affiliation")
affiliations## title
## 1 <NA>
## 2 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 3 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 4 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 5 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 6 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 7 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 8 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 9 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 10 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 11 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 12 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 13 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 14 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 15 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 16 Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method
## 17 Plant functional trait identity and diversity effects on soil meso-and macrofauna in an experimental grassland
## 18 Do invasive earthworms affect the functional traits of native plants?
## 19 Diplôme de Master 2 Mention Biodiversité—Écologie—Évolution Parcours DARWIN: Biologie Évolutive & Écologie
## affiliation
## 1 <NA>
## 2 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 3 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 4 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 5 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 6 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 7 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 8 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 9 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 10 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 11 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 12 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 13 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 14 German Centre for Integrative Biodiversity Research (iDiv) Halle-Jena-Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 15 Institute of Biology, University of Leipzig, Deutscher Platz 5e, 04103 Leipzig, Germany.
## 16 Institute of Ecology, Friedrich Schiller University of Jena, Dornburger Str. 159, 07743 Jena, Germany.
## 17 NOT FOUND
## 18 NOT FOUND
## 19 NOT FOUND
## City Country lat long
## 1 <NA> <NA> NA NA
## 2 Halle Germany 52.07 8.35
## 3 Jena Germany 50.93 11.58
## 4 Leipzig Germany 51.35 12.40
## 5 Leipzig Germany 51.35 12.40
## 6 Jena Germany 50.93 11.58
## 7 Jena Germany 50.93 11.58
## 8 Halle Germany 52.07 8.35
## 9 Jena Germany 50.93 11.58
## 10 Leipzig Germany 51.35 12.40
## 11 Leipzig Germany 51.35 12.40
## 12 Halle Germany 52.07 8.35
## 13 Jena Germany 50.93 11.58
## 14 Leipzig Germany 51.35 12.40
## 15 Leipzig Germany 51.35 12.40
## 16 Jena Germany 50.93 11.58
## 17 <NA> <NA> NA NA
## 18 <NA> <NA> NA NA
## 19 <NA> <NA> NA NAExample of outputs
Table of your publications
pub %>%
data.frame() %>%
select(Title = title, Authors = author,
Journal = journal, `Vol(Issue),page` = number,
Year = year) %>%
kableExtra::kable()| Title | Authors | Journal | Vol(Issue),page | Year |
|---|---|---|---|---|
| Testing soil nematode extraction efficiency using different variations of the Baermann-funnel method | S Cesarz, AE Schulz, R Beugnon, N Eisenhauer | Soil organisms | 91 (2), 61 | 2019 |
| Plant functional trait identity and diversity effects on soil meso-and macrofauna in an experimental grassland | R Beugnon, K Steinauer, AD Barnes, A Ebeling, C Roscher, … | Advances in Ecological Research | 61, 163-184 | 2019 |
| Do invasive earthworms affect the functional traits of native plants? | L Thouvenot, O Ferlian, R Beugnon, T Künne, A Lochner, MP Thakur, … | Frontiers in Plant Science | 12, 424 | 2021 |
| Diplôme de Master 2 Mention Biodiversité—Écologie—Évolution Parcours DARWIN: Biologie Évolutive & Écologie | R Beugnon | Montpellier SupAgro | 2018 |
Wordcloud of your manuscript titles
library("tm")
library("SnowballC")
library("wordcloud2")
# List of words to remove
list.stop = c('affect', 'effects', 'using')
docs <- Corpus(VectorSource(pub$title))
toSpace <- content_transformer(function (x , pattern ) gsub(pattern, " ", x))
docs <- docs %>%
tm_map(., toSpace, "/") %>%
tm_map(., toSpace, "@") %>%
tm_map(., toSpace, "\\|") %>%
tm_map(., content_transformer(tolower)) %>%
tm_map(., removeNumbers) %>%
tm_map(., removeWords, stopwords("english")) %>%
tm_map(., removeWords, list.stop) %>%
tm_map(., removePunctuation) %>%
tm_map(., stripWhitespace)
dtm <- TermDocumentMatrix(docs)
m <- as.matrix(dtm)
v <- sort(rowSums(m),decreasing=TRUE)
d <- data.frame(word = names(v),freq=v)
head(d, 10)## word freq
## soil soil 2
## functional functional 2
## baermannfunnel baermannfunnel 1
## different different 1
## efficiency efficiency 1
## extraction extraction 1
## method method 1
## nematode nematode 1
## testing testing 1
## variations variations 1col.pal = colorRampPalette(colors = c('brown','Darkgreen'))
wordcloud2(data = d,
size = 1,
color = col.pal(10))Map of your collaborators
library(rnaturalearth)
ggplot(data = ne_countries(scale = "medium", returnclass = "sf")) +
geom_sf() +
geom_point(data = affiliations,
aes(x = long, y = lat),
size = 2,
color = 'red',
fill = "blue") +
labs(x = '', y = '')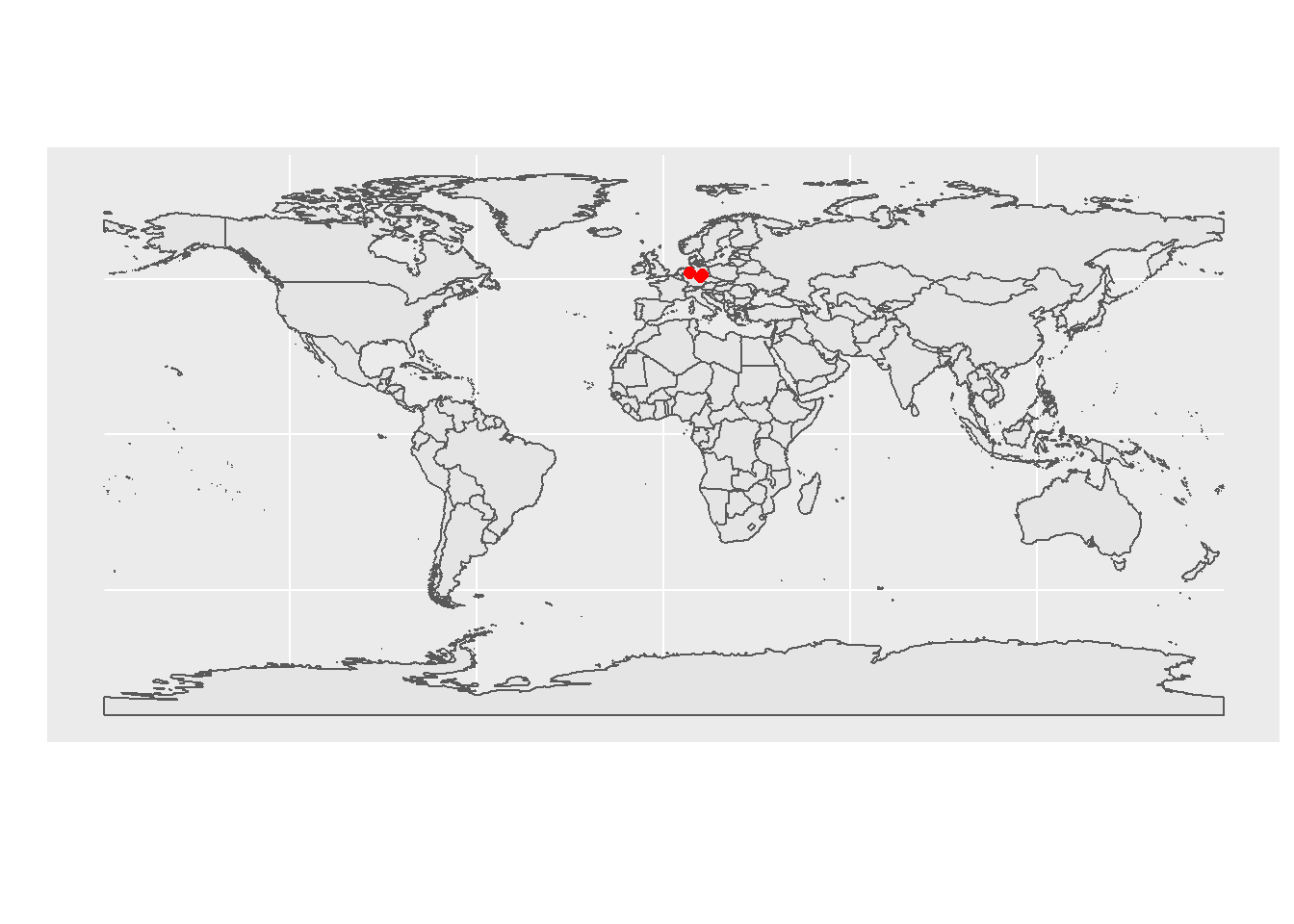
Rémy Beugnon
I am a PosDoc between iDiv, the CEFE and LIM working biodiversity-microclimate-ecosystem functioning nexus.